📋 Model Description
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- arxiv:2304.12244
- arxiv:2306.08568
- arxiv:2308.09583
- license:apache-2.0
- autotraincompatible
- endpointscompatible
- text-generation-inference
- region:us
- text-generation
MaziyarPanahi/WizardLM-2-7B-GGUF
- Model creator: microsoft
- Original model: microsoft/WizardLM-2-7B
Description
MaziyarPanahi/WizardLM-2-7B-GGUF contains GGUF format model files for microsoft/WizardLM-2-7B.Prompt template
{system_prompt}
USER: {prompt}
ASSISTANT: </s>or
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: {prompt} ASSISTANT: </s>......Taken from the original README
license: apache-2.0
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our release blog post and upcoming paper.
Model Details
- Model name: WizardLM-2 7B
- Developed by: WizardLM@Microsoft AI
- Base model: mistralai/Mistral-7B-v0.1
- Parameters: 7B
- Language(s): Multilingual
- Blog: Introducing WizardLM-2
- Repository: https://github.com/nlpxucan/WizardLM
- Paper: WizardLM-2 (Upcoming)
- License: Apache2.0
Model Capacities
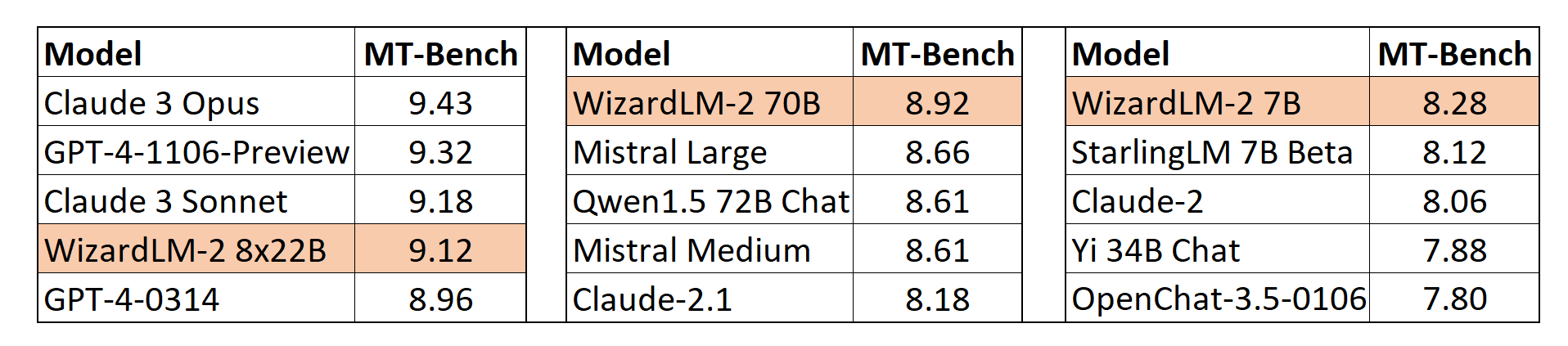
MT-Bench
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
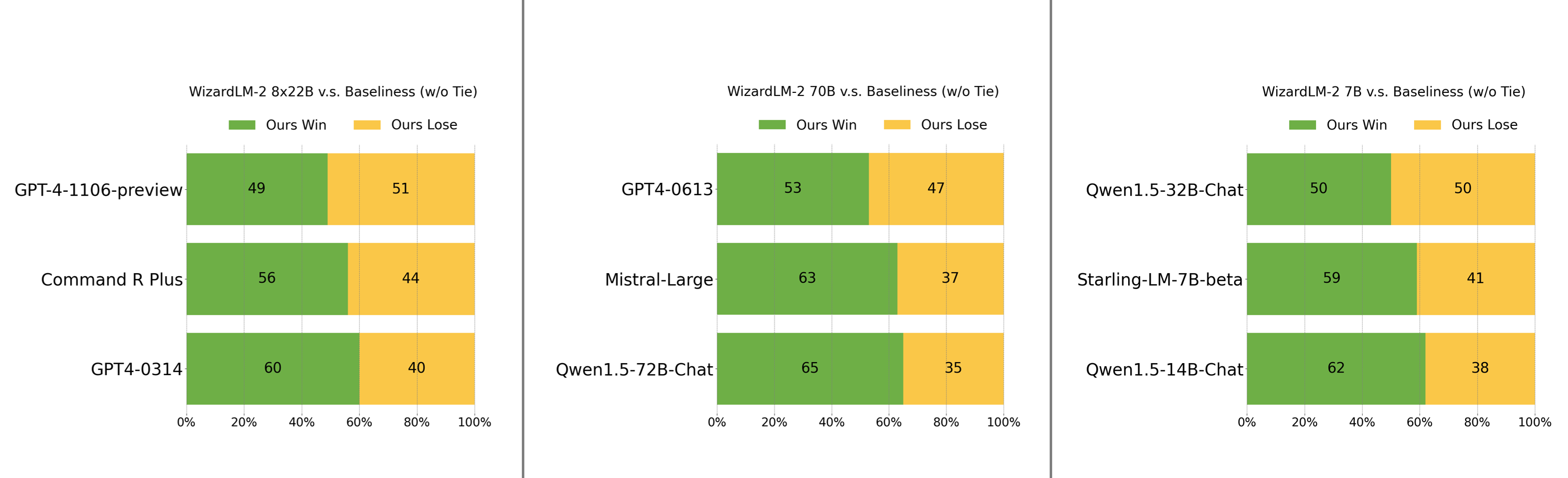
Human Preferences Evaluation
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
Method Overview
We built a fully AI powered synthetic training system to train WizardLM-2 models, please refer to our blog for more details of this system.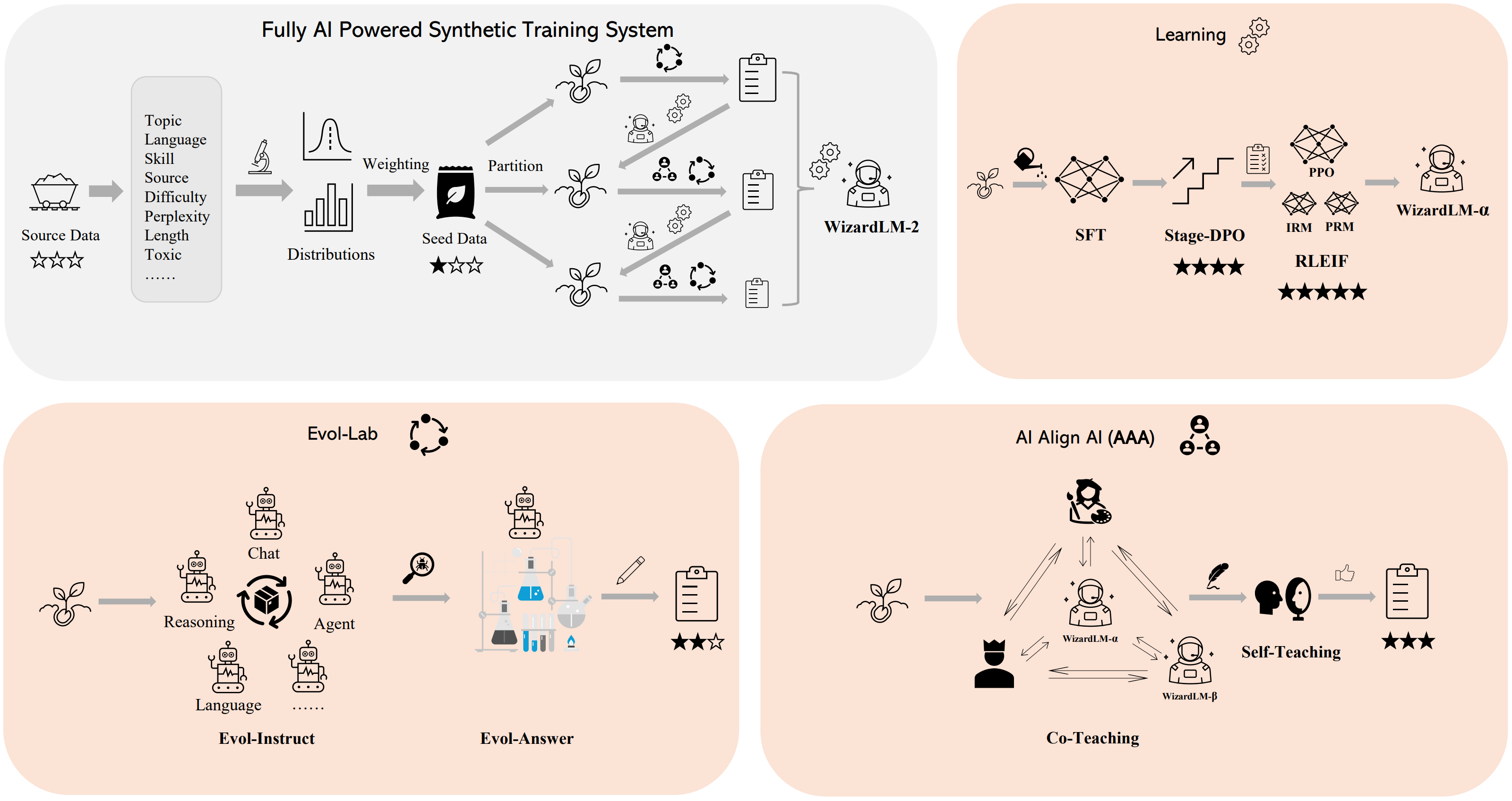
Usage
❗Note for model system prompts usage:
WizardLM-2 adopts the prompt format from Vicuna and supports multi-turn conversation. The prompt should be as following:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......Inference WizardLM-2 Demo Script
We provide a WizardLM-2 inference demo code on our github.
How to use
Thanks to TheBloke for preparing an amazing README on how to use GGUF models:About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
- llama.cpp. The source project for GGUF. Offers a CLI and a server option.
- text-generation-webui, the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
- KoboldCpp, a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
- GPT4All, a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
- LM Studio, an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
- LoLLMS Web UI, a great web UI with many interesting and unique features, including a full model library for easy model selection.
- Faraday.dev, an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
- llama-cpp-python, a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
- candle, a Rust ML framework with a focus on performance, including GPU support, and ease of use.
- ctransformers, a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
Explanation of quantisation methods
Click to see details
The new methods available are:
- GGMLTYPEQ2K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
- GGMLTYPEQ3K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
- GGMLTYPEQ4K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
- GGMLTYPEQ5K - "type-1" 5-bit quantization. Same super-block structure as GGMLTYPEQ4K resulting in 5.5 bpw
- GGMLTYPEQ6K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
How to download GGUF files
Note for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
In text-generation-webui
Under Download Model, you can enter the model repo: MaziyarPanahi/WizardLM-2-7B-GGUF and below it, a specific filename to download, such as: WizardLM-2-7B-GGUF.Q4K_M.gguf.
Then click Download.
On the command line, including multiple files at once
I recommend using the huggingface-hub Python library:
pip3 install huggingface-hubThen you can download any individual model file to the current directory, at high speed, with a command like this:
huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4KM.gguf --local-dir . --local-dir-use-symlinks FalseMore advanced huggingface-cli download usage (click to read)
You can also download multiple files at once with a pattern:
huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='Q4Kgguf'For more documentation on downloading with huggingface-cli, please see: HF -> Hub Python Library -> Download files -> Download from the CLI.
To accelerate downloads on fast connections (1Gbit/s or higher), install hf_transfer:
pip3 install hf_transferAnd set environment variable HFHUBENABLEHFTRANSFER to 1:
HFHUBENABLEHFTRANSFER=1 huggingface-cli download MaziyarPanahi/WizardLM-2-7B-GGUF WizardLM-2-7B.Q4KM.gguf --local-dir . --local-dir-use-symlinks FalseWindows Command Line users: You can set the environment variable by running set HFHUBENABLEHFTRANSFER=1 before the download command.
Example llama.cpp command
Make sure you are using llama.cpp from commit d0cee0d or later.
./main -ngl 35 -m WizardLM-2-7B.Q4KM.gguf --color -c 32768 --temp 0.7 --repeatpenalty 1.1 -n -1 -p "<|imstart|>system
{systemmessage}<|imend|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"Change -ngl 32 to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change -c 32768 to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the -p argument with -i -ins
For other parameters and how to use them, please refer to the llama.cpp documentation
How to run in text-generation-webui
Further instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model Tab.md.
How to run from Python code
You can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
How to load this model in Python code, using llama-cpp-python
For full documentation, please see: llama-cpp-python docs.
#### First install the package
Run one of the following commands, according to your system:
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
With NVidia CUDA acceleration
CMAKEARGS="-DLLAMACUBLAS=on" pip install llama-cpp-python
Or with OpenBLAS acceleration
CMAKEARGS="-DLLAMABLAS=ON -DLLAMABLASVENDOR=OpenBLAS" pip install llama-cpp-python
Or with CLBLast acceleration
CMAKEARGS="-DLLAMACLBLAST=on" pip install llama-cpp-python
Or with AMD ROCm GPU acceleration (Linux only)
CMAKEARGS="-DLLAMAHIPBLAS=on" pip install llama-cpp-python
Or with Metal GPU acceleration for macOS systems only
CMAKEARGS="-DLLAMAMETAL=on" pip install llama-cpp-python
In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKEARGS = "-DLLAMAOPENBLAS=on"
pip install llama-cpp-python#### Simple llama-cpp-python example code
from llama_cpp import Llama
Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
modelpath="./WizardLM-2-7B.Q4K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
ngpulayers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
Simple inference example
output = llm(
"<|im_start|>system
{systemmessage}<|imend|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
Chat Completion API
llm = Llama(modelpath="./WizardLM-2-7B.Q4KM.gguf", chatformat="llama-2") # Set chat_format according to the model you are using
llm.createchatcompletion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
📂 GGUF File List
| 📁 Filename | 📦 Size | ⚡ Download |
|---|---|---|
|
WizardLM-2-7B.IQ3_XS.gguf
LFS
Q3
|
2.81 GB | Download |
|
WizardLM-2-7B.IQ4_XS.gguf
LFS
Q4
|
3.67 GB | Download |
|
WizardLM-2-7B.Q2_K.gguf
LFS
Q2
|
2.53 GB | Download |
|
WizardLM-2-7B.Q3_K_L.gguf
LFS
Q3
|
3.56 GB | Download |
|
WizardLM-2-7B.Q3_K_M.gguf
LFS
Q3
|
3.28 GB | Download |
|
WizardLM-2-7B.Q3_K_S.gguf
LFS
Q3
|
2.95 GB | Download |
|
WizardLM-2-7B.Q4_K_M.gguf
Recommended
LFS
Q4
|
4.07 GB | Download |
|
WizardLM-2-7B.Q4_K_S.gguf
LFS
Q4
|
3.86 GB | Download |
|
WizardLM-2-7B.Q5_K_M.gguf
LFS
Q5
|
4.78 GB | Download |
|
WizardLM-2-7B.Q5_K_S.gguf
LFS
Q5
|
4.65 GB | Download |
|
WizardLM-2-7B.Q6_K.gguf
LFS
Q6
|
5.53 GB | Download |
|
WizardLM-2-7B.Q8_0.gguf
LFS
Q8
|
7.17 GB | Download |
|
WizardLM-2-7B.fp16.gguf
LFS
FP16
|
13.49 GB | Download |